
Sentiment Classification on Movie Reviews
Techniques for Sentiment Classification and Analysis for Data Mining
This is an intro to data mining project that covers some fundamental natural language processing techniques for a simple binary sentiment classifier. First I import all of the libraries I used for this project.
import pandas as pd
import io
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.model_selection import train_test_split
from sklearn.neighbors import KNeighborsClassifier
from sklearn.metrics import accuracy_score
from sklearn.preprocessing import StandardScaler
import nltk
nltk.download('wordnet')
from nltk.stem import WordNetLemmatizer
from nltk.tokenize import WhitespaceTokenizer
from sklearn.decomposition import PCA
import matplotlib.pyplot as plt
from sklearn.manifold import TSNE
import numpy as np
- Document vectorizer is the technique for feature extraction for this project
- K nearest neighbors is the classification technique for this project
- This is an intro to machine learning project that tries to predict and classify the sentiment of movie reviews
Next I import the data from txt sources.
file = io.open('train_new.txt', mode='r', encoding='utf-8')
text = file.read()
text = text.split('\n')
After importing the data, I split the data by each line and displayed in a data frame.
data = [line for line in text]
train_data_frame = pd.DataFrame(data, columns=['label'], dtype=pd.StringDtype())
train_data_frame[['label', 'review']] = train_data_frame['label'].str.split('\t', n=1, expand=True)
train_data_frame
| label | review | |
|---|---|---|
| 0 | +1 | One of my all-time favorite so-laughably-lousy... |
| 1 | -1 | I had high hopes for this film, because I thou... |
| 2 | -1 | When this was released, I thought this was one... |
| 3 | -1 | I just watched this movie on Starz. Let me go ... |
| 4 | +1 | I loved it so much that I bought the DVD and t... |
| ... | ... | ... |
| 24995 | +1 | It was a doubly interesting experience. For so... |
| 24996 | -1 | Wow what a great premise for a film : Set it a... |
| 24997 | -1 | A lot of death happens in the wild. You don't ... |
| 24998 | +1 | Corean cinema can be quite surprising for an o... |
| 24999 | +1 | Running Man isn't a great movie, in fact it's ... |
25000 rows × 2 columns
After collecting the data in the data frame, I use regex to perform some speedy text processing to remove punctuation stopwords and lowercase the text.
# lowercase
train_data_frame['review'] = train_data_frame['review'].str.lower()
stop_words = set(line.strip() for line in open('stopwords_en.txt'))
def remove_stop_words(text):
return[word for word in text if word not in stop_words]
# replace special characters with spaces
train_data_frame['review'] = train_data_frame['review'].replace({r'\W' : ' '}, regex = True)
train_data_frame['review'] = train_data_frame['review'].replace({r'\^[a-zA-Z]\s+' : ' '}, regex=True)
train_data_frame['review'] = train_data_frame['review'].replace({r'\s+[a-zA-Z]\s+' : ' '}, regex=True)
train_data_frame['review'] = train_data_frame['review'].replace({r'\s+\s+' : ' '}, regex=True)
lemmatizer = WordNetLemmatizer()
tokenizer = WhitespaceTokenizer()
def lemmatize_text(text):
return[lemmatizer.lemmatize(word) for word in tokenizer.tokenize(text)]
train_data_frame['review'] = train_data_frame['review'].apply(lemmatize_text)
# train_data_frame['review'] = train_data_frame['review'].apply(remove_stop_words)
train_data_frame['review'] = train_data_frame['review'].apply(lambda word : ' '.join(word))
train_data_frame
| label | review | |
|---|---|---|
| 0 | +1 | one of my all time favorite so laughably lousy... |
| 1 | -1 | i had high hope for this film because thought ... |
| 2 | -1 | when this wa released thought this wa one of t... |
| 3 | -1 | i just watched this movie on starz let me go t... |
| 4 | +1 | i loved it so much that bought the dvd and the... |
| ... | ... | ... |
| 24995 | +1 | it wa doubly interesting experience for some r... |
| 24996 | -1 | wow what great premise for film set it around ... |
| 24997 | -1 | a lot of death happens in the wild you don nee... |
| 24998 | +1 | corean cinema can be quite surprising for an o... |
| 24999 | +1 | running man isn a great movie in fact it kinda... |
25000 rows × 2 columns
After the raw text is processed, I use TFIDF, PCA, and a standard scaler to vectorize the documents.
Tfidf_Converter = TfidfVectorizer(max_features=250, min_df=0.1, max_df=0.7)
features = Tfidf_Converter.fit_transform(train_data_frame['review']).toarray()
scalar = StandardScaler()
analyzer = PCA(n_components=20)
features = scalar.fit_transform(features)
features = analyzer.fit_transform(features)
data = list(zip(train_data_frame['label'], features))
data_frame = pd.DataFrame(data, columns=['label', 'review'])
data_frame
| label | review | |
|---|---|---|
| 0 | +1 | [2.9633273974654846, 1.7398841424951845, 0.218... |
| 1 | -1 | [-0.2957745039373386, 1.20582577317322, 1.0810... |
| 2 | -1 | [0.06351597686652405, 1.49417093484336, -3.900... |
| 3 | -1 | [-2.0843046689986227, 2.5054442499402607, 0.39... |
| 4 | +1 | [1.1517302929771962, -1.7028205052355783, 0.13... |
| ... | ... | ... |
| 24995 | +1 | [4.086850379610443, 1.3361637765966505, 0.3590... |
| 24996 | -1 | [1.27568991055083, 1.3247409087211883, 0.82137... |
| 24997 | -1 | [-1.325654415412562, 2.6015278035933562, -1.30... |
| 24998 | +1 | [0.41016699322749367, 1.1861818963206265, 0.31... |
| 24999 | +1 | [-0.9508152804147036, -0.9337919909098141, 1.1... |
25000 rows × 2 columns
After processing the data, I use a train test split of 75% training data, 25% test data.
training_data, test_data, training_labels, test_labels = train_test_split(data_frame['review'], data_frame['label'], test_size=0.25, shuffle=True)
After splitting the data, I make a K Nearest Neighbors (KNN) classifier on the training data and check the accuracy for the test set.
classifier = KNeighborsClassifier(n_neighbors=250)
classifier.fit(list(training_data), list(training_labels))
predicted_labels = classifier.predict(list(test_data))
accuracy = accuracy_score(list(test_labels), list(predicted_labels))
print('Accuracy:', accuracy)
Accuracy: 0.7464
With the low accuracy of 74%, I want to observe the samples after they are vectorized in a 2D plot.
tsne = TSNE(n_components=2, perplexity=40, early_exaggeration=20, metric='cosine', random_state=None)
np_data = np.array(list(training_data))
np_labels = np.array(list(training_labels))
twoD_features = tsne.fit_transform(np_data)
plt.figure(figsize=(5,5))
plt.xlim(0, twoD_features[:,0].max())
plt.ylim(-100, 100)
positive = [x for i,x in enumerate(twoD_features) if np_labels[i] == '+1']
negative = [x for i,x in enumerate(twoD_features) if np_labels[i] == '-1']
plt.plot(positive, 'o', color='orange')
plt.plot(negative, 'o', color='blue')
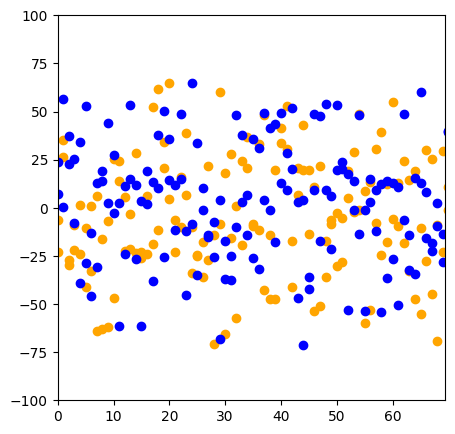
The resulting plot shows there is a strong overlap between both positive and negative reviews that have not been well separated by this vectorization process. For an intro to data mining project, this code is a preview of many techniques and libraries that are frequently used in data mining. But this project does not yield valuable results or insights. A better demonstration of the kind of insights that can be derived from data mining are the dog breeds project, and the efficacy of machine learning classifiers with the perceptrons project.